Linking to ImageMagick 6.9.12.98
Enabled features: fontconfig, freetype, fftw, heic, lcms, pango, raw, webp, x11
Disabled features: cairo, ghostscript, rsvgUsing 4 threadsimg <- image_read("bird.jpg")English version: Implementing Otsu’s Thresholding in R
大津の二値化は、画像処理において、グレースケール画像を二値化するための方法の一つです。 この方法は、画像のヒストグラムを分析して、最適な閾値を自動的に決定することで、画像を二値化します。 大津の二値化は、画像のコントラストが高い場合に特に効果的であり、背景と前景を明確に分けることができます。
大津の二値化はシンプルでありながら、効果的な方法であるため、画像処理の分野で広く使用されています。
筆者が初めて大津の二値化について学んだとき、感動したことを覚えています。 シンプルでありながら、効果的な方法で、美しいなと思いました。 今もよく使う方法の一つです。
基本的な考え方は、すべての可能な閾値について、クラス内分散とクラス間分散を計算し、クラス間分散が最大になる閾値を選択することです。 クラスというのは、二値化された画像において、白と黒の2つのクラスを指します。 クラス間分散が最大になる閾値は、画像のヒストグラムを最も効果的に分割する点であり、背景と前景を最も明確に分けることができるという考えです。
クラスについては、クラス0とクラス1、もしくは背景クラスと前景クラスと呼ぶことがあります。
とても簡単にまとめた流れは以下のようになります。
クラス内分散、クラス間分散、全体分散は、画像のヒストグラムを分析するための重要な概念です。 これらの分散の間には以下の関係性があります。
\[ \sigma_T^2 = \sigma_W^2 + \sigma_B^2 \]
ここで、\(\sigma_T^2\)は全体分散、\(\sigma_W^2\)はクラス内分散、\(\sigma_B^2\)はクラス間分散を表します。
つまり、クラス間分散が最大ということは、クラス内分散が最小であることを意味し、クラス内できれいに固まっているとも言えます。
今回二値化する画像は、以下のようなものを用意しました。

この画像は、私の家でかつて飼っていたセキセイインコの写真です。 名前は愛子ちゃん(あいちゃん)です。 とてもかわいいですね。
imagerのような画像処理のパッケージを使うと、Rで大津の二値化を簡単に実装できます。 しかし、今回は大津の二値化のアルゴリズムを理解するために、手動で実装してみたいと思います。
まずは画像を読み込みます。 画像の読み込みを手動で実装するのは大変なので、二値化以外の部分には、magickパッケージを使います。
magickについて
magickは、Rで画像処理を行うためのパッケージです。 画像の読み込み、変換、編集など、様々な機能を提供しています。 magick自体はもともとRの画像処理ライブラリではなく、CやC++で書かれたImageMagickという画像処理ライブラリのRバインディングです。
Linking to ImageMagick 6.9.12.98
Enabled features: fontconfig, freetype, fftw, heic, lcms, pango, raw, webp, x11
Disabled features: cairo, ghostscript, rsvgUsing 4 threadsimg <- image_read("bird.jpg")image_convert()関数を使って、画像をグレースケールに変換します。
img_gray <- image_convert(img, colorspace = "gray")
plot(img_gray)
次に、グレースケール画像のピクセル値を取得します。
dat <- image_data(img_gray, channels = "gray") # ピクセル値を取得
vals <- as.integer(dat) # ピクセル値を整数に変換ピクセル値の頻度をヒストグラムにまとめます。 ピクセル値は0から255の範囲にあるため、256個のビンを用意します。
h <- hist(vals, breaks = (-0.5):(255.5))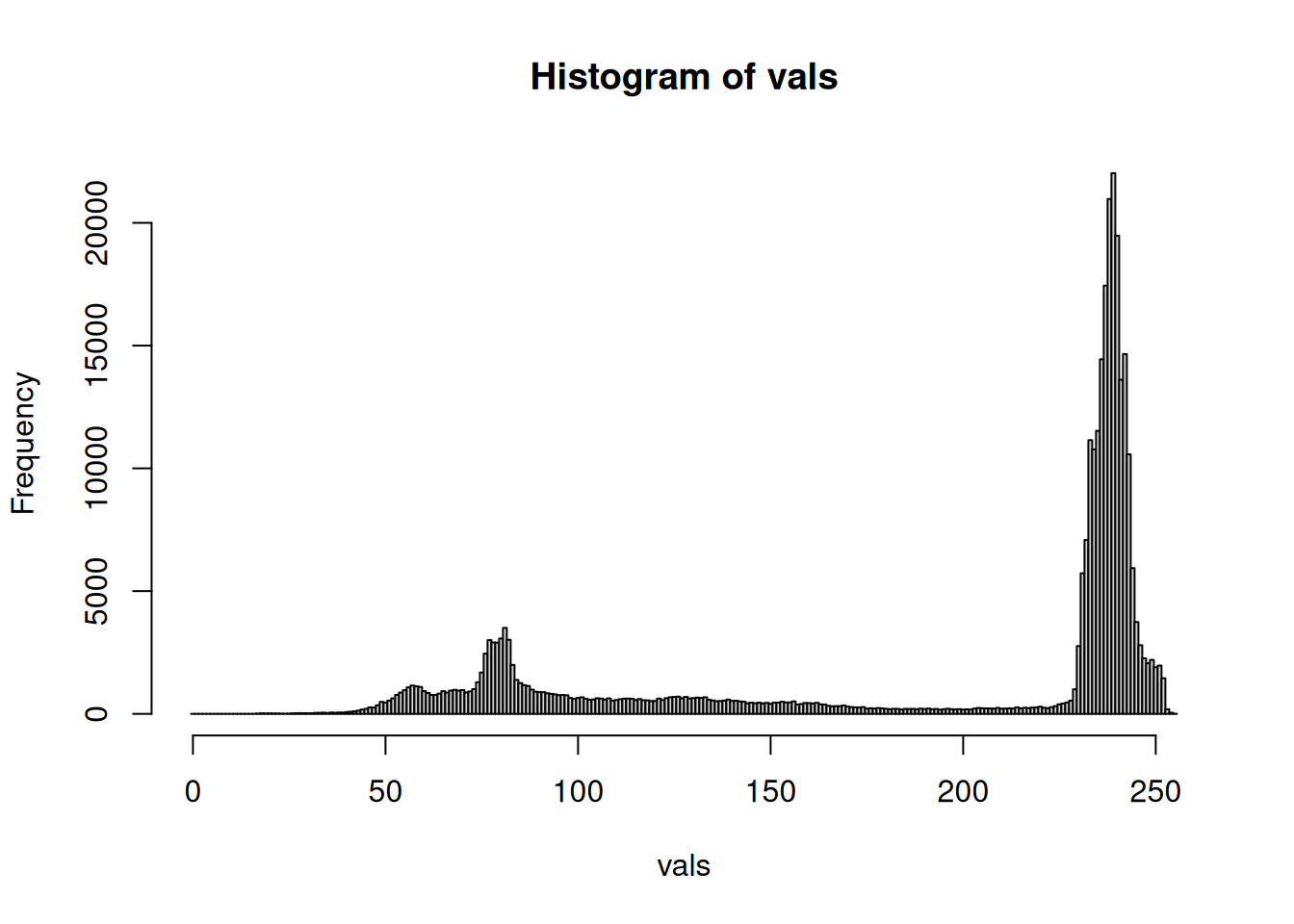
大津の二値化のアルゴリズムを実装します。 大津の二値化では、すべての可能な閾値について、クラス内分散とクラス間分散を計算し、クラス間分散が最大になる閾値を選択します。
以下のコードは、閾値を0から255まで変化させながら、クラス内分散とクラス間分散を計算する例です。
list_otsu <- lapply(seq_along(h$counts), function(i) {
t <- i - 1 # 0..L-1
p <- h$counts / sum(h$counts) # ヒストグラムを確率分布に変換
L <- length(p)
idx0 <- if (t >= 0) 0:t else integer(0) # 画素値の添字(0基準)
idx1 <- if (t + 1 <= L - 1) (t + 1):(L - 1) else integer(0)
# p は1基準なので +1 して参照
omega_0 <- sum(p[idx0 + 1])
omega_1 <- 1 - omega_0
# 総平均
mu_t <- sum((0:(L - 1)) * p)
# クラス平均(空クラスなら計算しない)
mu_0 <- if (omega_0 > 0) sum(idx0 * p[idx0 + 1]) / omega_0 else 0
mu_1 <- if (omega_1 > 0) sum(idx1 * p[idx1 + 1]) / omega_1 else 0
# クラス内分散(空クラスは寄与0にする)
var_0 <- if (omega_0 > 0) sum((idx0 - mu_0)^2 * p[idx0 + 1]) / omega_0 else 0
var_1 <- if (omega_1 > 0) sum((idx1 - mu_1)^2 * p[idx1 + 1]) / omega_1 else 0
var_w <- omega_0 * var_0 + omega_1 * var_1
# クラス間分散(空クラスの項は0)
term0 <- if (omega_0 > 0) omega_0 * (mu_0 - mu_t)^2 else 0
term1 <- if (omega_1 > 0) omega_1 * (mu_1 - mu_t)^2 else 0
var_b <- term0 + term1
# 全体分散
var_T <- sum(p * ((0:(L - 1)) - mu_t)^2)
c(
t = t,
omega_0 = omega_0, # クラス0の確率
omega_1 = omega_1, # クラス1の確率
mu_0 = mu_0, # クラス0の平均
mu_1 = mu_1, # クラス1の平均
mu_t = mu_t, # 総平均
var_0 = var_0, # クラス0の分散
var_1 = var_1, # クラス1の分散
var_w = var_w, # クラス内分散
var_b = var_b, # クラス間分散
var_T = var_T # 全体分散
)
})
df_otsu <- as.data.frame(do.call(rbind, list_otsu))
head(df_otsu) t omega_0 omega_1 mu_0 mu_1 mu_t var_0 var_1 var_w var_b
1 0 0 1 0 191.9755 191.9755 0 4692.817 4692.817 0
2 1 0 1 0 191.9755 191.9755 0 4692.817 4692.817 0
3 2 0 1 0 191.9755 191.9755 0 4692.817 4692.817 0
4 3 0 1 0 191.9755 191.9755 0 4692.817 4692.817 0
5 4 0 1 0 191.9755 191.9755 0 4692.817 4692.817 0
6 5 0 1 0 191.9755 191.9755 0 4692.817 4692.817 0
var_T
1 4692.817
2 4692.817
3 4692.817
4 4692.817
5 4692.817
6 4692.817最適な閾値は、クラス間分散が最大になる点で選択されます。
t_opt <- df_otsu$t[which.max(df_otsu$var_b)]
t_opt[1] 164今回の画像に対して、最適な閾値は 164 となります。
視覚的に確認するために、クラス内分散とクラス間分散のグラフを描いてみます。
plot(
df_otsu$t,
df_otsu$var_w,
ylim = c(0, max(df_otsu$var_w, df_otsu$var_b) * 1.1),
type = "l",
xlab = "Threshold",
ylab = "Within-class variance",
col = 2,
lwd = 3
)
lines(
df_otsu$t,
df_otsu$var_b,
type = "l",
xlab = "Threshold",
ylab = "Between-class variance",
col = 4,
lwd = 3
)
abline(v = t_opt, col = adjustcolor(7, alpha.f = 0.7), lwd = 3)
legend(
"topleft",
legend = c(
"Within-class variance",
"Between-class variance",
"Optimal threshold"
),
col = c(2, 4, 7),
lwd = 3,
bg = adjustcolor("white", alpha.f = 0.7)
)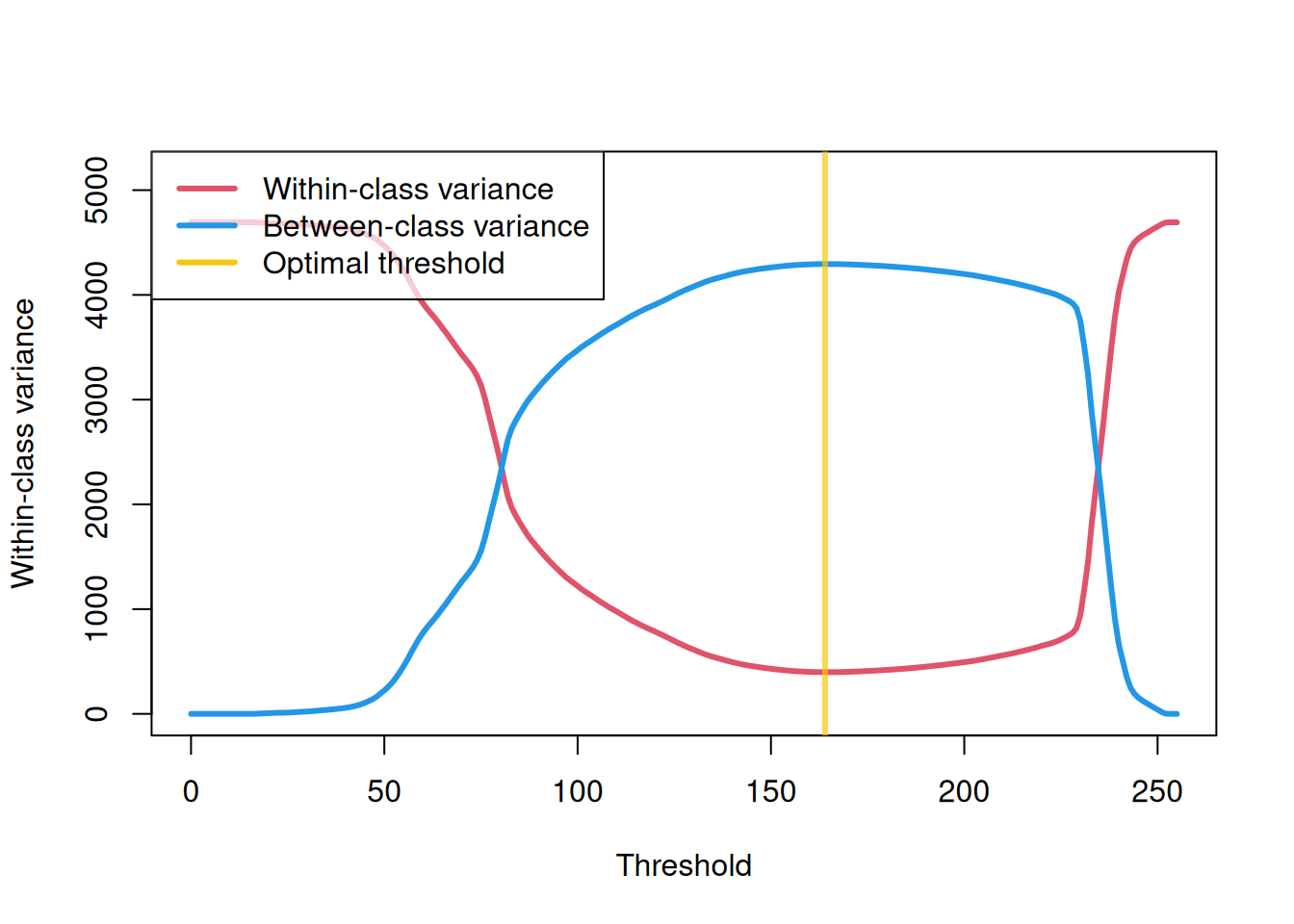
クラス内分散が最小で、クラス間分散が最大になる点が、最適な閾値であることがわかります。
また、この時の画像を二値化してみます。

なかなかきれいに二値化できているのがわかります。